

What really happened with WeWork?
What physics saw at WeWork’s peak that $4.4 billion couldn’t fix.

There’s no physics for organizational success and failure. There are frameworks—useful ones—but they explain after the fact. They can narrate any outcome. They can’t be wrong.
Genesis claims to be something different: a structural theory that generates falsifiable predictions, scores them, and publishes the results either way. Each entry in the Ledger either confirms the theory captures real structure or exposes where it breaks.
This entry tests whether Genesis could identify the specific architectural flaw, the mechanism of failure, and the behavioral response of leadership—using only what was known at WeWork’s highest point.

This is the third entry in the Ledger—where Genesis gets tested against real systems. This one’s already scored.
What this is: A scored retrodiction1—Genesis Theory applied to WeWork at peak private valuation (August 2017), predictions checked against the known path to bankruptcy (November 2023)
Where the evidence lives: Center for Open Science
How it scored: 15/15 directional accuracy. Combined Brier: 0.1362. Full scorecard published at genesistheory.org/wework.
How we know it wasn’t altered: The Seer registry on GitHub keeps scores hash-locked as SEER-2026-0004
In August 2017, Masayoshi Son toured a WeWork location in Manhattan. He was late and had just come from a meeting at Trump Tower. The tour lasted twelve minutes.
On the ride back, in the back seat of an SUV, Son sketched the outlines of a $4.4 billion investment on his iPad.
It was the second-largest private investment in an American startup, ever.
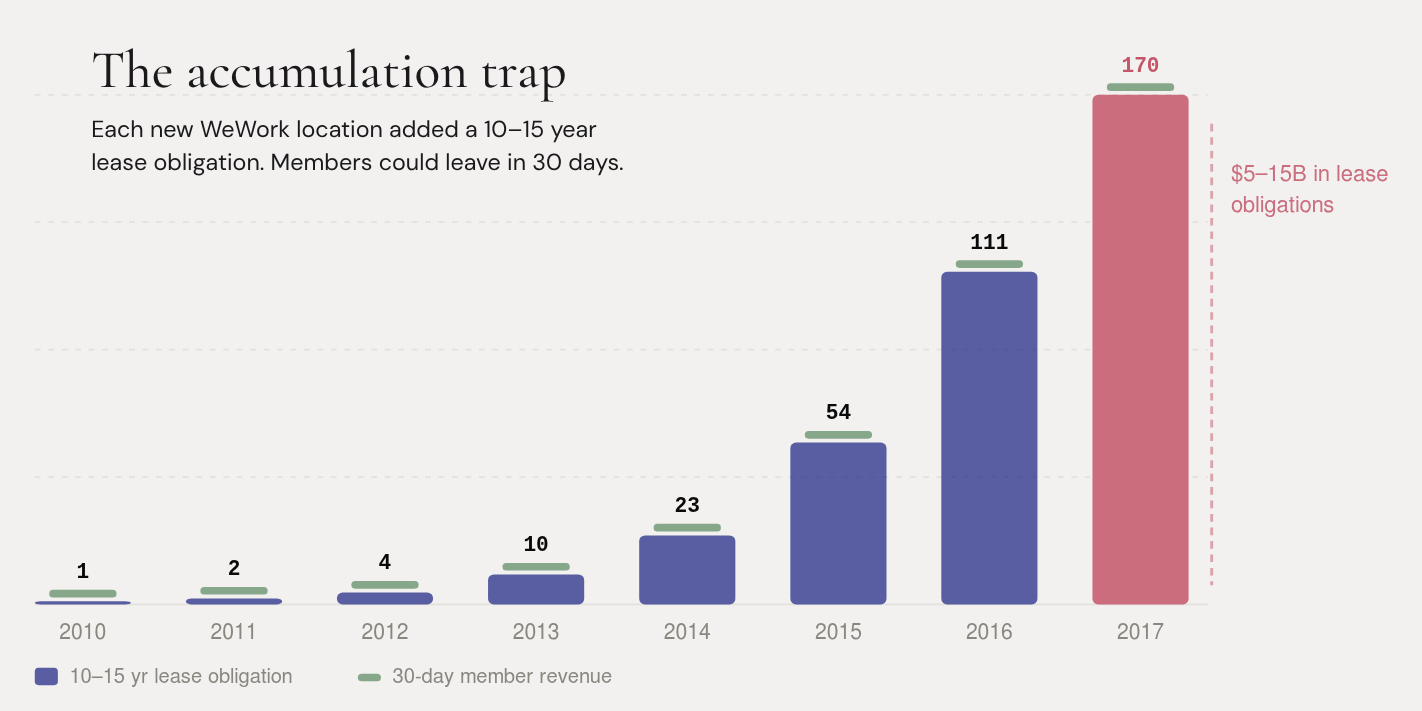
What did twelve minutes reveal? WeWork had 170 locations across 10 countries. Revenue was doubling annually. Members loved the product. The co-working market was growing 20–30% a year. Son saw the next Alibaba.
But twelve minutes is also what twelve minutes reveals about the structure of a business: nothing. The product, the energy, the growth—all visible. What drove the economics underneath—invisible.
WeWork’s 2016 financials told a simple story: $436 million in revenue, $429 million in losses. The company lost almost exactly as much as it earned. A ratio of 0.98 to 1.
That number didn’t set off alarms. In venture capital, losing money while growing fast is normal, expected even. Amazon lost money for years. So did Uber, Airbnb, and every other company that eventually dominated its category. Losses during hypergrowth aren’t a diagnosis. They’re a line item.
So what makes WeWork different?
The lease trap
Here’s where the structure matters.
When Amazon lost money, it was building warehouses, delivery networks, and cloud infrastructure—assets that would generate revenue for decades. The losses funded the construction of a machine. When the machine was built, the losses stopped and the margins grew.
WeWork’s losses funded something different. Each new location required signing a lease—typically 10 to 15 years long. WeWork committed to paying a landlord a fixed rent for a decade or more. Then it renovated the space, furnished it, and subleased it to members on month-to-month agreements.
Think about what that means structurally. WeWork is locked in for 10–15 years. Its members can leave in 30 days. If demand drops—a recession, a pandemic, or a shift in work patterns—WeWork absorbs the full cost of empty space while landlords collect their contracted rent.
This isn’t a growth-phase loss that resolves at scale. It’s an architectural mismatch. Every new location adds another 10-year obligation against month-to-month revenue. The more WeWork grew, the deeper this mismatch became.
By the time of Son’s twelve-minute tour, WeWork had somewhere between $5 and $15 billion in aggregate lease obligations. The exact number wasn’t public—WeWork was a private company and didn’t have to disclose it. That range is the best anyone could estimate in August 2017.
SoftBank invested $4.4 billion anyway.
The Kodak retrodiction tested Genesis on a company that failed because it couldn’t read reality accurately—it had the money, the technology, and the talent, and it even invented its own demise: the digital camera. But its ability to process accurate information was broken for twenty-one years.
WeWork showed something different. WeWork’s product worked. Members loved it. Enterprise clients were signing up. The co-working market was real. Unlike Kodak, there was nothing wrong with WeWork’s reading of its market.
The problem was more fundamental: the economic architecture of the business didn’t generate value. It consumed external capital to mask a loss-making operation that grew the losses as it grew the revenue.
Genesis tracks four dimensions that any organized system needs to convert opportunity into results:
Structural—can it build and deliver?
Informational—can it see reality clearly?
Relational—do its key partnerships help or hurt?
Foundational—does the underlying economics actually generate value? Can the system sustain itself from what it produces, or does it depend on external capital to cover the gap between what it earns and what it spends? This is the one that matters most for WeWork.
At peak, WeWork’s Structural scored 5.5—functional, the product scaled well. Informational scored 4.0—strained, the $20 billion “tech company” valuation had no technology behind it, but the distortion wasn’t yet absurd. Relational scored 5.5—SoftBank, Microsoft, enterprise clients, landlords all engaged. Foundational scored 3.0—loss equals revenue, duration mismatch, entirely dependent on external capital.
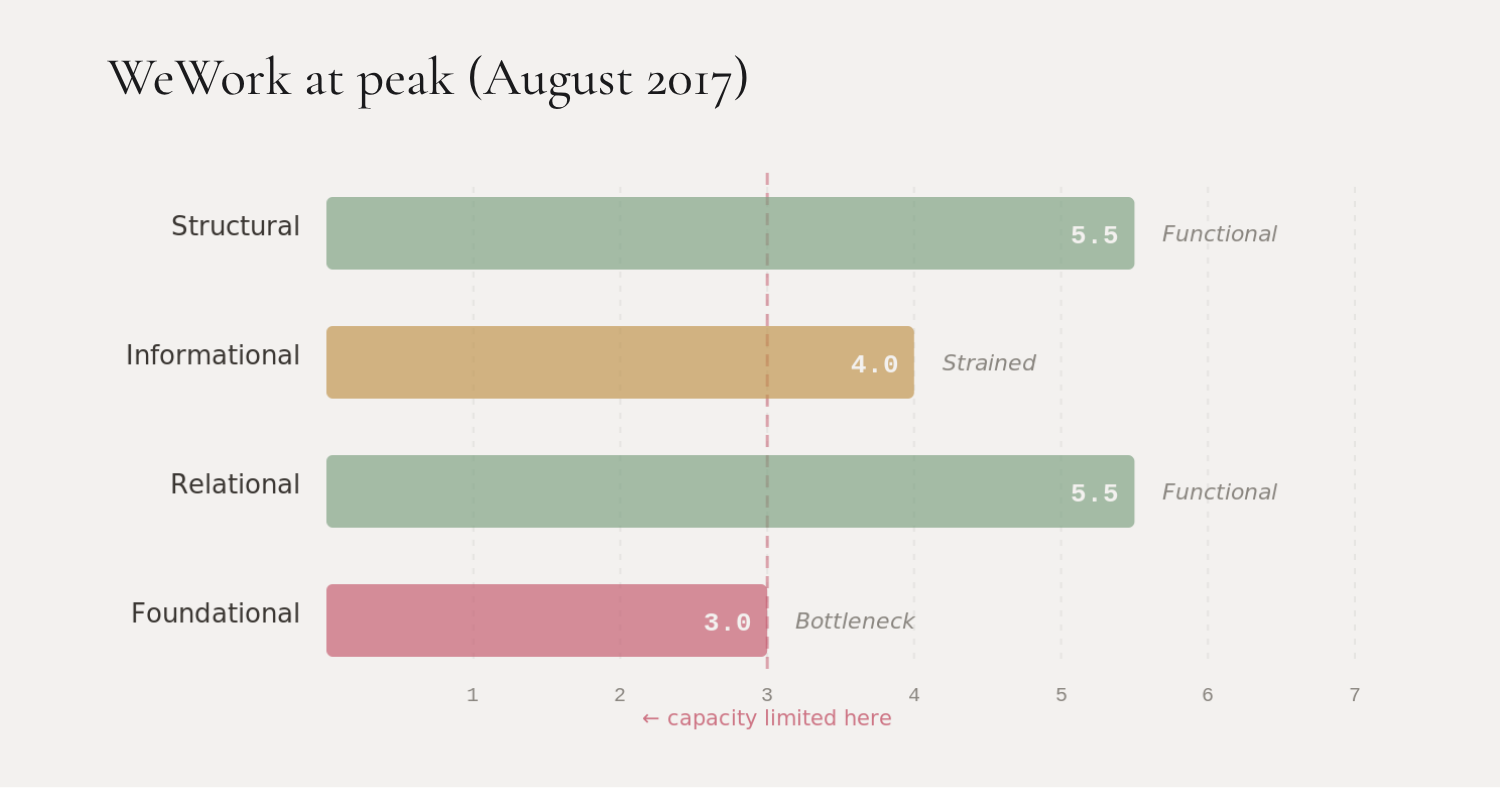
Foundational was the bottleneck. And physics says: a system’s capacity gets limited by its weakest channel, not its strongest.
Think of it like a restaurant with an incredible chef, beautiful design, great location, and loyal regulars—but the kitchen loses money on every plate it serves. Doubling the number of customers doubles the losses. No amount of marketing, expansion, or investor confidence fixes the per-plate economics. Yet… you can mask it with someone else’s money—for a time. But masking isn’t fixing.
That’s WeWork in August 2017. Genesis diagnosed it as a system in Crisis—normalized capacity of 0.21 on a 0-to-1 scale. Not yet terminal, but structurally impaired in a way that growth alone can’t resolve.
The bull case
Before we score the predictions, there’s something important the Kodak retrodiction didn’t require: a genuine bull case.
The bull case for WeWork in August 2017 wasn’t a fantasy. It ran like this:
WeWork was seven years old and doubling annually. In contrast, IWG (formerly Regus), the largest co-working company in the world, took over twenty years to reach profitability.
Startups lose money during hypergrowth—that’s the business model, not a flaw. Enterprise clients (Microsoft, Fortune 500 companies) were signing up and their contracts were stickier and higher-value than individual memberships. The flexible workspace market was growing 20–30% annually. SoftBank’s $4.4 billion provided at least 24 months of runway regardless of operating losses.
None of these arguments were wrong. Enterprise adoption did grow (to 32% of members by 2019). The flex-work trend was real (it accelerated during COVID). The runway was long enough to sustain operations for years.
The Genesis retrodiction includes this bull case at full strength, because intellectual honesty demands it. And it’s why the Upside scenario received a real probability (20%) rather than a token 5%. The bull case was defensible.
This is also why confidence was capped. WeWork at peak was a private company—it had one year of financial data, no occupancy rates, no per-location economics, and no disclosed lease obligations beyond a rough $5–15 billion range.
The evidence was thin. And when the evidence is thin, Genesis says so. We set a confidence ceiling3 of 0.58—meaning no prediction could exceed 58% confidence, regardless of how strong the structural read felt.
We couldn’t assign 85% confidence to “WeWork won’t achieve positive margin” even though the structural logic was compelling, because the evidence quality didn’t support that level of certainty.
The bull case turned out to be wrong. Enterprise economics never changed the per-unit losses. Growth amplified the lease obligations faster than it improved margins. But from August 2017 evidence alone, you couldn’t prove that. You could see the structural vulnerability. You couldn’t be certain it was fatal.
That’s the 0.58 ceiling in action. Not a hedge—a measurement of what the evidence actually supports.
The control: WeWork vs. IWG
If WeWork went bankrupt because co-working doesn’t work as a business, then the whole diagnosis is interesting but unremarkable. Lots of bad business models fail.
But co-working does work as a business. We know because IWG proved it.
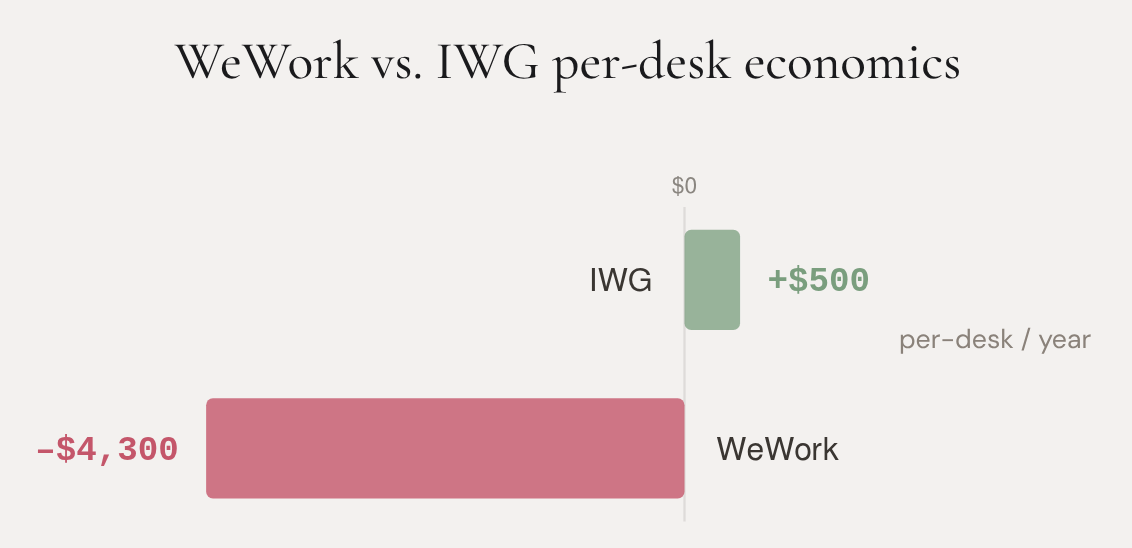
IWG operated in the same market, the same cities, during the same years. By 2017, it had 3,300 locations across 120 countries—roughly twenty times WeWork’s footprint. It was publicly traded. It was profitable. It made approximately $500 per desk per year.
WeWork lost approximately $4,300 per desk per year.
Same product category. Same demand trend. Same macroeconomic environment. Opposite outcomes.
The difference isn’t management quality or brand or timing. The difference is structural—how each company connected its economics to the market it served.
IWG used a mix of revenue-share agreements, franchise models, and management contracts. When demand dropped, landlords absorbed some of the downside. Risk was distributed across the system.
WeWork used pure long-term subleases. When demand dropped, WeWork absorbed everything. Risk was concentrated entirely on one party.
The physics calls this field coupling—how tightly a system’s economics depend on external conditions remaining favorable. IWG’s coupling was moderate: it could survive a downturn. WeWork’s coupling was extreme: it could only survive while capital was cheap, demand was rising, and no one tested the model.
This matters because it isolates the diagnosis. The market didn’t kill WeWork. WeWork’s economic architecture killed WeWork. A different architecture—serving the same customers, in the same buildings, during the same years—produced profitability, survival, and growth for IWG.
The Foundational channel was WeWork’s bottleneck. Not the field or the market. The internal economic structure that could never generate margins regardless of how fast it grew.
The navigator
There’s one more piece the Kodak retrodiction couldn’t test at T0 (standing at peak, using only what was known at the time). At Kodak’s peak (1996), Genesis identified a broken correction mechanism—the company’s ability to update its model when reality pushed back.
That diagnosis was testable because Kodak had 21 years of documented instances in which leadership deflected disconfirming information, starting with Steve Sasson’s camera in 1975.
At WeWork’s peak, Genesis couldn’t run that test. Adam Neumann had never faced a major disconfirming signal. Revenue was growing. Members were happy. SoftBank just invested. Every signal reinforced the existing model. The correction rate—how fast a leader updates their map when reality contradicts it—was untested.
Genesis noted this honestly: “the navigator might be visionary or delusional; T0 evidence cannot distinguish.”
Then the test arrived.
In December 2018, the $16 billion SoftBank mega-deal collapsed. This was the first serious crack—the biggest potential investor in the world looked at the numbers and pulled back.
A leader who updates on disconfirmation would pause. Reassess. Ask uncomfortable questions about unit economics. Maybe slow expansion. Maybe restructure the lease book. Maybe bring in outside governance.
Neumann launched the “We Company” rebrand in January 2019. The new mission: to “elevate the world’s consciousness.”
The correction rate dropped to near zero. The system responded to its biggest challenge with more narrative, not reassessment.
Genesis had predicted this (BET-8, confidence 0.45—low, because the evidence was thin). It was the moment the diagnosis sharpened. At T0, we couldn’t distinguish between visionary and delusional. At T1, the distinction was clear.
What Genesis called—and what it couldn’t
Here’s the scorecard. The split between groups tells the story.
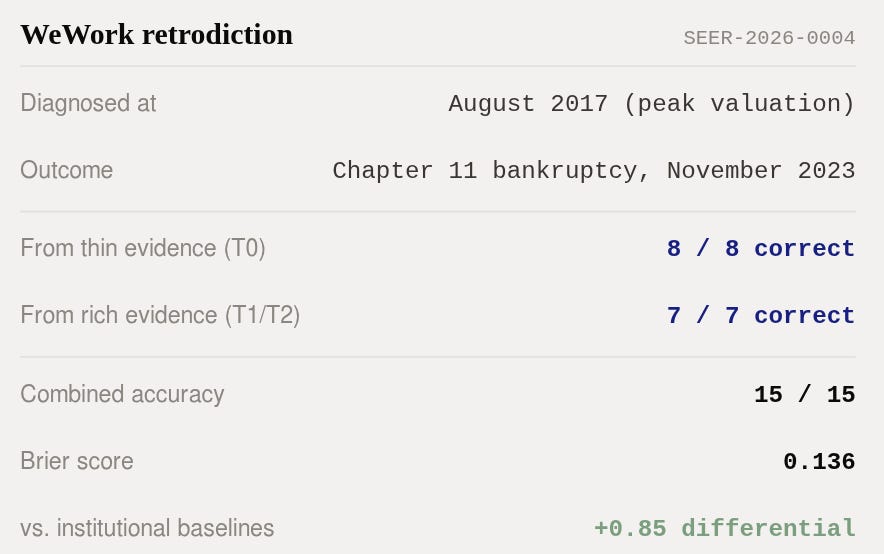
Eight predictions from thin evidence—a private company, one year of financials, no occupancy data. All eight correct, but at low confidence (mean 0.54). Brier score: 0.217. The framework saw the right things, but couldn’t be sure how right it was.
Seven predictions from rich evidence—after the $16 billion deal collapse, the S-1 filing, the first hard financial data. All seven correct at high confidence (mean 0.81). Brier score: 0.042. The framework earned its precision as the picture came into focus.
This is what early detection actually looks like. Not a bold call with high conviction. A directional signal with appropriate humility about magnitude and timing. “Something is structurally wrong here, but I can’t tell you exactly how wrong, or exactly when it breaks.” Then the evidence improves—and the signal sharpens.
From August 2017 evidence (confidence capped at 0.58):
No positive margin within 24 months → correct (never achieved)
Additional capital required within 24 months → correct ($702 million bond at 8 months)
Enterprise boundary most resilient → correct (SPAC pitched on enterprise)
No self-correction before forced correction → correct (zero preparation)
Lease mismatch becomes binding constraint → correct ($47.2 billion → bankruptcy)
Disproportionate impact vs. IWG → correct (WeWork bankrupt; IWG thrived)
Margin stays negative for 24 months → correct (never approached zero)
Navigator rigidity on first challenge → correct (rebrand instead of reassessment)
From January 2019 and August 2019 evidence (confidence 0.70–0.90):
SoftBank forced to intervene within 18 months → correct ($10 billion bailout at 9 months)
IPO fails or prices below 50% of $47 billion → correct (IPO failed entirely)
Neumann removed within 12 months of S-1 → correct (41 days)
15%+ locations closed within 24 months → correct (well above threshold)
Margin negative through all 2020 → correct (bankrupt by 2023)
Enterprise is last to degrade → correct (SPAC pitched on enterprise)
No voluntary preparation before forced correction → correct (zero)
Combined: 15 for 15. Brier: 0.136. Differential accuracy: +0.85 vs. baselines.
For comparison:
SoftBank invested $4.4 billion at T0 calling WeWork the “next Alibaba” and eventually wrote down $14 billion in total losses. Goldman Sachs and JPMorgan underwrote the IPO at $47 billion—the IPO failed entirely. Fidelity marked its position down to $18.3 billion—still 2.5 times the eventual bailout value. Short sellers identified the lease risk—correct direction, but couldn’t predict the behavioral dynamics or the structural cascade.
Genesis saw the structure. It also saw the navigator. And it read the specific mechanism by which the model would fail—not “the leases are risky” but “the economic architecture concentrates all downside risk on a single party that generates no margin, masked by a single capital source, governed by a single individual with unchecked control, who will respond to the first challenge by escalating the narrative rather than updating the model.”
That’s a structural diagnosis. Available in August 2017, if you knew how to read it.
The evidence scrub
One more thing—and it’s about our process, not results.
The original version of this retrodiction used data that wasn’t actually available in August 2017. Eleven items had crept into the T0 evidence package: 2017 full-year financials (not disclosed until April 2018), per-desk loss data, precise lease obligations, occupancy rates, and several other figures that became available later.
We caught it and scrubbed everything.
Every claim in the evidence package now carries a publication date. Every item that fails the August 2017 cutoff was displaced to a later window. The diagnostic and prediction were rebuilt from scratch using only the 29 claims that survived the scrub.
This cost us. The original T0 classified the system as Terminal—normalized capacity of 0.14. The scrubbed T0 classifies it as Critical—0.21. The confidence ceiling dropped from 0.72 to 0.58. Several dramatic findings—including the precise cascade pathway and the navigator’s self-dealing—were correctly attributed to later checkpoints instead of T0.
The Brier score got worse: 0.136 versus the original’s 0.040.
But the science got better. A retrodiction that uses future data to diagnose the past is just storytelling with math. The scrub protocol—now mandatory for all Genesis cases—forces the analysis to earn its conclusions from the evidence that was actually available.
The hidden lesson: with honest baselines, the decline from T0 to T1 was steeper than the contaminated version showed. The system deteriorated faster than we originally credited, because the contaminated T0 was already reflecting mid-decline data.
What this proves (and what it doesn’t)
Two retrodictions down. Two different failure types.
Kodak was an informational channel failure. The company couldn’t read reality. Three CEOs, twenty-one years of suppressed correction, and a persistent model error that treated photography as physical output while the world moved to digital communication. Cash couldn’t purchase model accuracy.
WeWork was a foundational channel failure. The economics didn’t work. Loss equaled revenue. Every new location deepened the structural vulnerability. Capital masked the weakness but couldn’t fix it. A profitable competitor in the same market proved the failure was architectural, not environmental.
Together, they demonstrate that Genesis reads across different bottleneck types and different failure mechanisms. It isn’t pattern-matching one kind of failure—it’s structural diagnosis that adapts to wherever the binding constraint actually sits.
But both are retrodictions. The outcome was known. Despite evidence scrubs and hard cutoffs and publication dates on every claim, the analyst knew the ending. You can mitigate hindsight bias. You can’t eliminate it.
That’s why the Tesla prediction exists. Same instrument. Same protocols. Same chain-of-custody. But this time, the ending hasn’t happened yet.
Kodak and WeWork calibrate the instrument. Tesla tests it.
Full materials: genesistheory.org/wework
Registry: SEER-2026-0004
The Ledger: predictions, retrodictions, and calibration reviews. We publish the results either way. If you found this interesting, and would like to submit a prediction or a retrodiction, email us at research@genesistheory.org.
A “retrodiction” applies a framework to a historical case using only evidence available at the time, then scores the diagnosis against what actually happened. The opposite of a prediction—same rules, known ending.
A Brier score measures how well your confidence matched reality—0.0 means perfect calibration, 0.25 means you’d have done just as well flipping a coin.
A “confidence ceiling” caps how sure any prediction can be, based on how much evidence you actually have. Thin evidence means low ceilings—regardless of how compelling the structural logic feels.